Не великий секрет - я користуюся Windows XP і наразі для мене це найкраща ОС. А заради відчуття красивого вмикаю я згладжування шрифтів ClearType.
Ось тільки кілька місяців тому змушений був відмовитися, адже на новому моніторі це згладжування виглядало просто огидно. Але не так давно знайшов прикольну тулзу від майкрософта http://www.microsoft.com/typography/ClearTypePowerToy.mspx.
Після вельми простої конфігурації, я отримав хорошу якість згладжування шрифтів.
System.nanoTime() and measurements
I'm still using simple
But for some algorithms, especially in development environment
But, everyone will say that it is not important what way of implementation you'll choose if difference is less than 1ms. It doesn't matter. And they will be right. In this case it doesn't matter what is faster, even if production amount of data is much more than testing amount of data and this may affect execution time significantly. Algorithm does matter.
It always depends on algorithm!
System.currentTimeMillis() when need to test performance of some part of code. It's fast and easy to use, especially to profile some algorithm while coding; performance still is an important measure used to choose between few algorithms or choose the best way how to implement algorithm.But for some algorithms, especially in development environment
System.currentTimeMillis() doesn't give any valuable results as it's hard to choose between 0ms and 0ms returned for both algorithms :) System.nanoTime() can used in such situations. It helps to get precise measurement of code execution time.But, everyone will say that it is not important what way of implementation you'll choose if difference is less than 1ms. It doesn't matter. And they will be right. In this case it doesn't matter what is faster, even if production amount of data is much more than testing amount of data and this may affect execution time significantly. Algorithm does matter.
It always depends on algorithm!
JBoss Richfaces Refcard is ready for free download
DZone provides a list of free to download and use refcards for different technologies and tools (like IDE). Few days ago new refcard was release, and it's about JBoss Richfaces. You may download it here http://refcardz.dzone.com/refcardz/richfaces.
At page http://refcardz.dzone.com/ you may download more and more refcards for yourself. Some time ago I've downloaded for Eclipse, my favorite IDE IntellijIDEA, Spring, Groovy etc. And now downoloading JBoss Richfaces refcard too.
At page http://refcardz.dzone.com/ you may download more and more refcards for yourself. Some time ago I've downloaded for Eclipse, my favorite IDE IntellijIDEA, Spring, Groovy etc. And now downoloading JBoss Richfaces refcard too.
Presentations and articles about scalable software architecture
Last week was searching for interesting articles and presentations with samples of scalable and failure tolerant architecture. As result, my bookmarks increased with a number of new links to articles and videos.
Articles:
Videos & presentations:
Articles:
- Scalability Principles
- SEDA
- Large codebase organization with Spring
- Building Scalability and Achieving Performance: A Virtual Panel
- Scalability Worst Practices
- Shard Lessons
- Asynchronous Architectures [4]
- Thoughts on Development
- Hitting the scalability wall - Amdahl's Law
- 10 Lessons in Scalability from MySpace
- Twitter as a scalability case study
Videos & presentations:
- Randy Shoup on eBay's Architectural Principles
- Architecture Evaluation in Practice
- Availability & Consistency
- Architecting for Latency
- The Design and Architecture of InfoQ
- Architecture Quality: Operational Manageability
- How to scale your web app
- Behind the Scenes at MySpace.com
- Scaling Twitter
Cловники в предметній області
Словники предметної області займають вельми важливе місце при проектуванні та розробці програмного забезпечення. Не менш частіше використовуються словники в предметній області. В даному випадку, словниками можуть виступати невеликі набори даних в стилі ключ-значення, або більш складні, де кожному ключу відповідає набір значень. Прикладів таких словників є безліч, наприклад, словник країн, словник типів кредитних карточок, словник пріоритетів задач, і більш складніші словники матеріалів та продукції (за окремими вийнятками) тощо.
Ця стаття розповідає про моє бачення такого "патерна" як Словник. Важливо визначитися, що саме слід вважати словником в предметній області.
Словник – це набір термінів пов’язаних між собою певною областю використання, які проте рідко змінюються. Частіше всього, словники використовуються, для того, щоб надати користувачам вибір значень з певної множити, наприклад, країну проживання, стать, посаду тощо.
Словники складаються з записів, які собою являють пару ключ-значення. В залежності від значення словники бувають простими та складними. Простий словник, це коли певному ключу відповідає одне значення, а складний словник – ключу відповідає набір значення. Наприклад, якщо коду країни відповідає тільки назва цієї країни, то цей словник є простим, де ключем виступає код країни. Прикладом складного словника є словник матеріалів, де коду товару відповідає його назва, вартість, країна виробник, маса тощо.
Складні словники можуть бути складеними. Складеним словником називається такий, в якого одне із значень є елементом іншого словниками. Наприклад, дано складний словник країн, в якому певному коду відповідають назва та код типу країни (республіка, федерація, королівство тощо). Код типу країни вказує на словник типів країн, таким чином словник країни можна вважати складеним та залежним від словника типів країн.
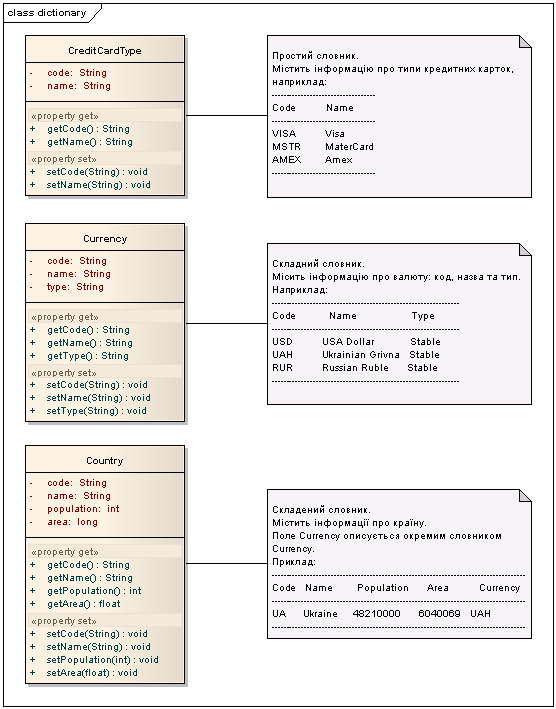
Рис 1 – Різні типи словників.
Словники часто використовують при розробці програмного забезпечення, адже дають можливість групувати набори даних в окремі групи, використовувати їх в групах та асоціювати певне значення з групою. В предметної області певний набір даних може бути словником, якщо він не виступає центральним в даній предметній області. Словники повинні залишатися максимально спрощеним та піддававтися мінімальним змінам в процесі використання, в той час як центральні сутності предметної можуть бути дуже складними та змінювати часто.
Чим складніший словник, тим більше програмний продукт залежить від нього. Словники можуть з часом переростати на повноцінні набори даних. При цьому збільшується або їх складності або кількість даних.
Зі словників часто починається проектування та кодування програм, вони є об’єктом перевикористання. Якщо використовувати необхідні словники спроектовані та закодовані на попередніх проектах, то можна скоротити час на написання нових проектів. Розроблений словник може виступати незалежним компонентом, але подібні компоненти буває тяжко спроектувати, адже вони вимагають гнучкості в роботі, а також тісної залежності від них іншого коду.
Існує кілька способів зберігання даних словників: набори констант, енумерації, файли, база даних тощо. Використання констант та енумерації для зберігання елементів словника пожуть значно покращити процес кодувати та збільшити читабельність коду, але при цьому частіше всього ми втрачаємо можливість швидкої зміни «захардкодженого» набору даних. Звичайно, словник статей, може бути спокійно закодований у вигляді енумерації, але словник країн ні. Те, що словники змінюються рідко не значить, що вони ніколи не міняються. В окремих випадках є необхідність добавити нові елементи або виконати користування існуючих, і в залежності від типу програми, найкращими будуть тут зберігання словників у файлах та базах даних.
Ще однією хорошою практикою є змістовні ключі словників. Простіше працювати та підтримувати в роботі словники, що містять ключі, які легко зрозуміти та отримати інформацію про сам елемент словника. Цього тяжко досягнути якщо використовувати числові ідентифікатори. Наприклад, для словника типів кредитних карточок ключі VISA, MSTR, AMEX тощо зручніше використовувати, ніж, наприклад, 1, 2, 3. У випадку використання бази даних для зберігання словників також простіше писати запити.
Оскільки словники містять невеликі набори даних і в основному рідко змінюються, то вони частіше легко піддаються кешуванню. Але тут слід не забувати, що словники теж можуть міняти, тому програма повинна підтримувати або можливість обновити дані в кеші або виконати інвалідацію кеша або ж увімкнути підтримку дати закінчення терміни дії кешу, після якого нові дані будуть знов закешовані.
Для зберігання та використання словників можна також використовувати і інші способи. Наприклад, якщо використовується MySQL, то для роботи із таблицями з словниками можна використвувати MyISAM engine, адже він найкраще підходить для даних, що рідко змінуюються, але частіше зчитуються. Таблиці із словниками частіше піддаються повному кешуванню СУБД, а використання сладених індексів на всі колонки БД може взагалі позбавити необхідность у фізичному вводі-виводі. Збереження словників у базі даних та використання зовнішніх ключів покращує цілісність даних, і знову ж таки, не сильно впливає на ресурси для виконання запитів.
Ця стаття розповідає про моє бачення такого "патерна" як Словник. Важливо визначитися, що саме слід вважати словником в предметній області.
Словник – це набір термінів пов’язаних між собою певною областю використання, які проте рідко змінюються. Частіше всього, словники використовуються, для того, щоб надати користувачам вибір значень з певної множити, наприклад, країну проживання, стать, посаду тощо.
Словники складаються з записів, які собою являють пару ключ-значення. В залежності від значення словники бувають простими та складними. Простий словник, це коли певному ключу відповідає одне значення, а складний словник – ключу відповідає набір значення. Наприклад, якщо коду країни відповідає тільки назва цієї країни, то цей словник є простим, де ключем виступає код країни. Прикладом складного словника є словник матеріалів, де коду товару відповідає його назва, вартість, країна виробник, маса тощо.
Складні словники можуть бути складеними. Складеним словником називається такий, в якого одне із значень є елементом іншого словниками. Наприклад, дано складний словник країн, в якому певному коду відповідають назва та код типу країни (республіка, федерація, королівство тощо). Код типу країни вказує на словник типів країн, таким чином словник країни можна вважати складеним та залежним від словника типів країн.
Рис 1 – Різні типи словників.
Словники часто використовують при розробці програмного забезпечення, адже дають можливість групувати набори даних в окремі групи, використовувати їх в групах та асоціювати певне значення з групою. В предметної області певний набір даних може бути словником, якщо він не виступає центральним в даній предметній області. Словники повинні залишатися максимально спрощеним та піддававтися мінімальним змінам в процесі використання, в той час як центральні сутності предметної можуть бути дуже складними та змінювати часто.
Чим складніший словник, тим більше програмний продукт залежить від нього. Словники можуть з часом переростати на повноцінні набори даних. При цьому збільшується або їх складності або кількість даних.
Зі словників часто починається проектування та кодування програм, вони є об’єктом перевикористання. Якщо використовувати необхідні словники спроектовані та закодовані на попередніх проектах, то можна скоротити час на написання нових проектів. Розроблений словник може виступати незалежним компонентом, але подібні компоненти буває тяжко спроектувати, адже вони вимагають гнучкості в роботі, а також тісної залежності від них іншого коду.
Існує кілька способів зберігання даних словників: набори констант, енумерації, файли, база даних тощо. Використання констант та енумерації для зберігання елементів словника пожуть значно покращити процес кодувати та збільшити читабельність коду, але при цьому частіше всього ми втрачаємо можливість швидкої зміни «захардкодженого» набору даних. Звичайно, словник статей, може бути спокійно закодований у вигляді енумерації, але словник країн ні. Те, що словники змінюються рідко не значить, що вони ніколи не міняються. В окремих випадках є необхідність добавити нові елементи або виконати користування існуючих, і в залежності від типу програми, найкращими будуть тут зберігання словників у файлах та базах даних.
Ще однією хорошою практикою є змістовні ключі словників. Простіше працювати та підтримувати в роботі словники, що містять ключі, які легко зрозуміти та отримати інформацію про сам елемент словника. Цього тяжко досягнути якщо використовувати числові ідентифікатори. Наприклад, для словника типів кредитних карточок ключі VISA, MSTR, AMEX тощо зручніше використовувати, ніж, наприклад, 1, 2, 3. У випадку використання бази даних для зберігання словників також простіше писати запити.
Оскільки словники містять невеликі набори даних і в основному рідко змінюються, то вони частіше легко піддаються кешуванню. Але тут слід не забувати, що словники теж можуть міняти, тому програма повинна підтримувати або можливість обновити дані в кеші або виконати інвалідацію кеша або ж увімкнути підтримку дати закінчення терміни дії кешу, після якого нові дані будуть знов закешовані.
Для зберігання та використання словників можна також використовувати і інші способи. Наприклад, якщо використовується MySQL, то для роботи із таблицями з словниками можна використвувати MyISAM engine, адже він найкраще підходить для даних, що рідко змінуюються, але частіше зчитуються. Таблиці із словниками частіше піддаються повному кешуванню СУБД, а використання сладених індексів на всі колонки БД може взагалі позбавити необхідность у фізичному вводі-виводі. Збереження словників у базі даних та використання зовнішніх ключів покращує цілісність даних, і знову ж таки, не сильно впливає на ресурси для виконання запитів.
Subscribe to:
Posts (Atom)