Нарешті відбувся реліз IntellijIDEA 9.0.
Для мене це було неочікувано, хоча користуюся EAP'ами вже давно. Перейшов через підтримку FreeMarker та Velocity. А пізніше добавилась перевірка коректності слів по словнику, відчутно покращилася швидкодія в останніх EAP версіях, можливість назначати кольори окремим групам файлів, потім добавилося code folding для дженериків та анонімних класів та багато іншого. Цікаво також, що є можливість генерити діаграми класів, діаграми змінених класів, підключення до Jira та YouTrack для роботи із тасками.
Версія 9.0 вийшла в двох редакція: повнофункціональна Ultimate Edition з підтримкою JavaEE та великої кількості плагінів, а також безкоштовної з відкритим кодом Community Edition.
Корисні посилання:
1. IntellijIDEA blog
2. IDEA what's new
Задумався я над UML. Вчу студентів, що це дуже корисна річ, часто використовується в реальному світі. Допомогає не тільки спроектувати програму, але і донести свою думку до інших, зрозуміти чужу програму; є важливою частина документації.
І справді, UML буває корисним для того, щоб спроектувати програму, якщо це взагалі можливо зробити в повній мірі. Донести думку до інших за допомогою UML - річ також нетривіальна, хоча все залежить. Щодо технічної документації, то я прихильник думки, що найкраща документація - це сам код програми (доречі тут можна почитати про це більше).
А ще часто доводиться чути думки, що UML - це зайве, що все в голові можна спроектувати, і при цьому особливо "ясно видно динаміку". Інші не розуміють, навіщо ці квадратики та кружочки; a це й чоловічок (которий актор, чи то пак актант) взагалі смішно виглядає. Інші і не знають про це або знають, але не пробували.
Кожному своє. Я ж використовую UML, точніше ту частину, що мені справді допомагає. Я не пробую спроектувати всю систему, бо зазвичай це є неможливо через складність, величину системи чи плинність вимог. І звичайно я не завжди використовую UML, тільки коли це потрібно.
Натомість при розробці певної функції програми, що виходить поза межі стандартних шаблонів та правил проекту не можу обійтися без діаграм випадків використання, класів та послідовностей. Цих трьох діаграм для мене достатньо.
Спершу визначити список випадків використання та їх сценарії, як результат визначити список додаткових питань та білих плям в специфікації. Після цього вже на основі прецендентів паралельно будуються діаграми класів та послідовностей. Роблю це все на листочку або на боарді. Зазвичай, починаю з основного і закінчую другорядними класами та зв'язками. Найцікавіше потім переробити систему, починаючи з найпростіших другорядних класів та закінчуючи основними. Наступне просіювання починається при написанні коду. Знову ж таки, писати починаю з найпростіших і/або другорядних класів. Це не тільки дає час подумати над удосконаленням основних класів та інтерфейсів, а також прощупати це все ручками в коді, визначити білі плями, розбіжності та несходження.
Ось так вона, думка, спочатку матеріалізується на бумазі, відточується, потім перетворюється в код, і ще раз відточується.
І взагалі, дуже цікаву книжку Крега Лармана Применение UML 2.0 и шаблонов проектирования. Якщо є перша версія, то можна почитати її, як це колись зробив я. Раджу всім, особливо студентам, що хочуть зрозуміти принципи проектування та розробки ОО програмного забезпечення.
І справді, UML буває корисним для того, щоб спроектувати програму, якщо це взагалі можливо зробити в повній мірі. Донести думку до інших за допомогою UML - річ також нетривіальна, хоча все залежить. Щодо технічної документації, то я прихильник думки, що найкраща документація - це сам код програми (доречі тут можна почитати про це більше).
А ще часто доводиться чути думки, що UML - це зайве, що все в голові можна спроектувати, і при цьому особливо "ясно видно динаміку". Інші не розуміють, навіщо ці квадратики та кружочки; a це й чоловічок (которий актор, чи то пак актант) взагалі смішно виглядає. Інші і не знають про це або знають, але не пробували.
Кожному своє. Я ж використовую UML, точніше ту частину, що мені справді допомагає. Я не пробую спроектувати всю систему, бо зазвичай це є неможливо через складність, величину системи чи плинність вимог. І звичайно я не завжди використовую UML, тільки коли це потрібно.
Натомість при розробці певної функції програми, що виходить поза межі стандартних шаблонів та правил проекту не можу обійтися без діаграм випадків використання, класів та послідовностей. Цих трьох діаграм для мене достатньо.
Спершу визначити список випадків використання та їх сценарії, як результат визначити список додаткових питань та білих плям в специфікації. Після цього вже на основі прецендентів паралельно будуються діаграми класів та послідовностей. Роблю це все на листочку або на боарді. Зазвичай, починаю з основного і закінчую другорядними класами та зв'язками. Найцікавіше потім переробити систему, починаючи з найпростіших другорядних класів та закінчуючи основними. Наступне просіювання починається при написанні коду. Знову ж таки, писати починаю з найпростіших і/або другорядних класів. Це не тільки дає час подумати над удосконаленням основних класів та інтерфейсів, а також прощупати це все ручками в коді, визначити білі плями, розбіжності та несходження.
Ось так вона, думка, спочатку матеріалізується на бумазі, відточується, потім перетворюється в код, і ще раз відточується.
І взагалі, дуже цікаву книжку Крега Лармана Применение UML 2.0 и шаблонов проектирования. Якщо є перша версія, то можна почитати її, як це колись зробив я. Раджу всім, особливо студентам, що хочуть зрозуміти принципи проектування та розробки ОО програмного забезпечення.
Apache JMeter
Попрацював сьогодні трохи з JMeter. Давно знаю про цю програму, давно хотів навчитися її використовувати, але до сьогодні якось не складалося.
Загальне враження від неї позитивне: простий інтерфейс, зручне представлення тесту у вигляді дерева, чітко визначений життєвий цикл тесту та послідовність виконання кожного елементу тесту дозволяют швидко накидати та запустити тест. А набір лістенерів дозволяють представити отримані дані зберегти та представити у зручному вигляді: таблиці із детальними та середніми значеннями, графіки тощо.
Звичайно необовязково запускати JMeter у візуальному режимі. Можна також скористатися режимом командного рядка або сервера для розприділеного тестування. Включивши навантажувальні тести JMeter в процес збірки певних версії проекту (наприклад, тестових версій, чи спеціальних щотижневих версій), можна контролювати метрику швидкодії програми. І все це безкоштовно.
Сьогодні використовувати її проте прийшлося тільки для перевірки середньої швидкодії програми при різних навантаженнях на різних серверів. Висновок: трохи треба попрацювати над швидкодією окремих речей. А ще планую підготувати декілька простих тестових випадків і періодично знімати метрики зміни швидкодії та масштабування в процесі розробки.
Особливо цікаво також було порівняти зібраних даних з серверів та мого ноутбука. Висновок: настав час придбати собі нового звіра :).
Корисні посилання:
1. JMeter User Manual
2. http://www.scribd.com/doc/7499267/Load-Testing-With-JMeter
3. JMeter tips
Загальне враження від неї позитивне: простий інтерфейс, зручне представлення тесту у вигляді дерева, чітко визначений життєвий цикл тесту та послідовність виконання кожного елементу тесту дозволяют швидко накидати та запустити тест. А набір лістенерів дозволяють представити отримані дані зберегти та представити у зручному вигляді: таблиці із детальними та середніми значеннями, графіки тощо.
Звичайно необовязково запускати JMeter у візуальному режимі. Можна також скористатися режимом командного рядка або сервера для розприділеного тестування. Включивши навантажувальні тести JMeter в процес збірки певних версії проекту (наприклад, тестових версій, чи спеціальних щотижневих версій), можна контролювати метрику швидкодії програми. І все це безкоштовно.
Сьогодні використовувати її проте прийшлося тільки для перевірки середньої швидкодії програми при різних навантаженнях на різних серверів. Висновок: трохи треба попрацювати над швидкодією окремих речей. А ще планую підготувати декілька простих тестових випадків і періодично знімати метрики зміни швидкодії та масштабування в процесі розробки.
Особливо цікаво також було порівняти зібраних даних з серверів та мого ноутбука. Висновок: настав час придбати собі нового звіра :).
Корисні посилання:
1. JMeter User Manual
2. http://www.scribd.com/doc/7499267/Load-Testing-With-JMeter
3. JMeter tips
Freemarker Tips
I like FreeMarker. It's simple, functional and pretty fast tool.
In project we are using Freemaker with SpringMVC.
To work with message bundle are used few macros, one of them is
Unfortunately it's not so easy :(. The macros is calling method that accepts arguments as an array of objects. And string
where
Another interesting thing about Freemarker is the way you can print numbers. If you want to print number value in argument X as a regular number rather than formatted number, you may do it in next way ${X?c}. I always forget to add ?c suffix and later receive many errors. Fortunately, it's possible to use #{X} that has the same effect. I found that it saves my time.
In project we are using Freemaker with SpringMVC.
To work with message bundle are used few macros, one of them is
spring.messageArgs. So today I've spent some time on searching how to pass argument to it. There was only one argument and, obviously, I was expecting that this macros could be used in next way:<@spring.messageArgs "some.message.key" "argumentValue"/>
Unfortunately it's not so easy :(. The macros is calling method that accepts arguments as an array of objects. And string
"argumentValue" isn't an array. So I found next simple solution:<#assign args = ["Ruslan"]/>
<@spring.messageArgs "hello.man" args/>
where
hello.man = Hello {0}!Another interesting thing about Freemarker is the way you can print numbers. If you want to print number value in argument X as a regular number rather than formatted number, you may do it in next way ${X?c}. I always forget to add ?c suffix and later receive many errors. Fortunately, it's possible to use #{X} that has the same effect. I found that it saves my time.
Code Generation at Java
Some time ago I found how the code generation techniques are used at Java.
Java NIO exposes a set of Buffer interfaces with package level implementations that are returned while creating buffers. If you will look at those implementation classes (HeapByteBuffer or DirectByteBuffer) you will notice that they are generated. Look at the file header comments - and you will see notion that it's generated and the name of the template. You may find templates with description of it's parameters here.
Java NIO exposes a set of Buffer interfaces with package level implementations that are returned while creating buffers. If you will look at those implementation classes (HeapByteBuffer or DirectByteBuffer) you will notice that they are generated. Look at the file header comments - and you will see notion that it's generated and the name of the template. You may find templates with description of it's parameters here.
Code Generation
We are writing the code and this is our job. That's the art that we make. We put our thoughts, our patient, our soul to make it ideal or near to ideal. Sometimes we just write the code asap as there is no time or code is simple or we wrote similar code hundreds of times. This small article is about writing similar code again and again.
When we are writing similar code second or fourth time it's not an art and it is tedious. But that's useful to polish previous code: we can find and fix bugs, add needed logging, rewrite with better performance, make the code clean and handy to read and change etc. Often we are changing previously written code to make it better as well.
But what if you need to write similar code tens or hundreds of times? Will you change previous 20 classes because now you find the best algorithm or fixed the annoying problem with performance? Will you be glad to fix 50 classes over the project because just now you find the bug? (so it must be fixed, right?)
That will take your time, that you could spend on coding something interesting or studying some new popular technology or have a beer with your friends. And what about customer for whom this software is a business.
That's why I'm writing about code generation, the thing we all know and use often. You remember, when you're creating new project or adding new class with your favorite IDE, you got initial code so you can write your important part rather that spend time on writing the same code again and again.
While reviewing code generation tools we can divide them into external and internal. External are provided by IDE or other providers (remember famous xdoclet toolkit?). Internal is written by your team and used withing some one or few projects.
Internal code generators could be simple enough to generate only basic template source code or UI that will be changed and extended. It also can be large and complex to generate layers (domain types, DAOs and repositories etc) of your software.
Lets review next types of code generators:
1. template code generators
2. partial code generators
Template code generators run once at the begin. They are responsible for generating source code that will be rewritten or extended by developer. It's important to have clean generated code with comments for generated code and for placements where to put your code. It's good to use such generators if you have already ideal code to be generated. Ideal means that you will not need ever to change template and regenerate the same code again and again. Regenerating code will remove code written by developers with hands.
Partial code generators could be run as much as you will need. They are separated from code written by developers. For C# that would be good to use partial keyword (as I remember partial class declaration was added to have distinct generated and written by developer code for WinForms and ASP.NET); for Java extending could be used as well. We use generator to generate only similar code and put in another file, e.g. partial class definition or base abstract class. The specific code is written in derived class. While we find new bugs and improvements we need just to change templates or generator configuration and regenerate the code again.
Although code is generated it also must be easy to read it. Document your code, as you need to do it only once - in templates, so don't be lazy and stingy! For partial code generator or template code generator that is twice as important, as you are working directly with generated code.
Don't forget to add comment with notion that code is generated automatically and can be regenerated again, so other developers will think twice before changing it by hands!
Also remember that it's okay to add code generation to project step-by-step. For example, I'm the only who is using the new generator for now. I need to do so to find and fix defects, find the parts of code that could and must be generated, improve configuration and way of use. In this case the generated base code (with partial code generator) is commited too.
Use the best tools to write templates. For example I'm using Freemarker template engine to describe templates and generate source code. There are few code generators that read configuration file and generate appropriate code. For such tools performance is not as important as flexibility of templates and configuration.
Document the generator. Share source code within team. Put your generator into source code repository near to the project, but not into it. Also make and tag latest stable version as runnable scripts or program, so other developers can update and use it without spending on it additional time.
When we are writing similar code second or fourth time it's not an art and it is tedious. But that's useful to polish previous code: we can find and fix bugs, add needed logging, rewrite with better performance, make the code clean and handy to read and change etc. Often we are changing previously written code to make it better as well.
But what if you need to write similar code tens or hundreds of times? Will you change previous 20 classes because now you find the best algorithm or fixed the annoying problem with performance? Will you be glad to fix 50 classes over the project because just now you find the bug? (so it must be fixed, right?)
That will take your time, that you could spend on coding something interesting or studying some new popular technology or have a beer with your friends. And what about customer for whom this software is a business.
That's why I'm writing about code generation, the thing we all know and use often. You remember, when you're creating new project or adding new class with your favorite IDE, you got initial code so you can write your important part rather that spend time on writing the same code again and again.
While reviewing code generation tools we can divide them into external and internal. External are provided by IDE or other providers (remember famous xdoclet toolkit?). Internal is written by your team and used withing some one or few projects.
Internal code generators could be simple enough to generate only basic template source code or UI that will be changed and extended. It also can be large and complex to generate layers (domain types, DAOs and repositories etc) of your software.
Lets review next types of code generators:
1. template code generators
2. partial code generators
Template code generators run once at the begin. They are responsible for generating source code that will be rewritten or extended by developer. It's important to have clean generated code with comments for generated code and for placements where to put your code. It's good to use such generators if you have already ideal code to be generated. Ideal means that you will not need ever to change template and regenerate the same code again and again. Regenerating code will remove code written by developers with hands.
Partial code generators could be run as much as you will need. They are separated from code written by developers. For C# that would be good to use partial keyword (as I remember partial class declaration was added to have distinct generated and written by developer code for WinForms and ASP.NET); for Java extending could be used as well. We use generator to generate only similar code and put in another file, e.g. partial class definition or base abstract class. The specific code is written in derived class. While we find new bugs and improvements we need just to change templates or generator configuration and regenerate the code again.
Although code is generated it also must be easy to read it. Document your code, as you need to do it only once - in templates, so don't be lazy and stingy! For partial code generator or template code generator that is twice as important, as you are working directly with generated code.
Don't forget to add comment with notion that code is generated automatically and can be regenerated again, so other developers will think twice before changing it by hands!
Also remember that it's okay to add code generation to project step-by-step. For example, I'm the only who is using the new generator for now. I need to do so to find and fix defects, find the parts of code that could and must be generated, improve configuration and way of use. In this case the generated base code (with partial code generator) is commited too.
Use the best tools to write templates. For example I'm using Freemarker template engine to describe templates and generate source code. There are few code generators that read configuration file and generate appropriate code. For such tools performance is not as important as flexibility of templates and configuration.
Document the generator. Share source code within team. Put your generator into source code repository near to the project, but not into it. Also make and tag latest stable version as runnable scripts or program, so other developers can update and use it without spending on it additional time.
ToStringBuilder and multi-thread environment
Just found some article about using Apache Commons'
Well, there were few projects where I was able to use Apache Commons Lang tool called
and as result got a string with nice-look instance description. It was perfect for me.
But now I'm not using this tool. And wasn't using it for the last 10 months as well. I would be happy to use it rather than own implementation over
ToStringBuilder tool and about what a wonderful tool it is. And I decided to write about it too.Well, there were few projects where I was able to use Apache Commons Lang tool called
ToStringBuilder. It's very useful tool that helps to print information about class instance in the toString() method. I just was need to write
@Override
public String toString() {
return new ToStringBuilder(this, ToStringStyle.SHORT_PREFIX_STYLE)
.append("Id", id)
.append("Name", name)
.append("Description", description)
.toString();
}
and as result got a string with nice-look instance description. It was perfect for me.
But now I'm not using this tool. And wasn't using it for the last 10 months as well. I would be happy to use it rather than own implementation over
StringBuilder but I can't. ToStringBuilder has problems with running in multi-thread environment. If you have class A that uses ToStringBuilder and you're going to use instances of this class in different threads - be careful!
Google Books
English version by Google Translate
Не секрет, що у світі Google Books відбуваються чималі зміни.
Про це все розказує сам Google.
Сервіс дуже цікавий, і сподіваюся кількість повністю доступних та щойно виданих книхо з часом збільшиться. Адже є книжки, яких вже і не купиш, а є книжки - як хочеться купити або навіть потрібно купити, але змушений часто це робити без перегляду хоч якогось контенту. Гугл може дати можливість віртуального швидкого перегляду книжки перед купівлею, - наче ви в справжньому магазині.
Подобається також можливість створювати власну бібліотеку. Або вставляти фрейв сторінку із книжкою :)
Не секрет, що у світі Google Books відбуваються чималі зміни.
Про це все розказує сам Google.
Сервіс дуже цікавий, і сподіваюся кількість повністю доступних та щойно виданих книхо з часом збільшиться. Адже є книжки, яких вже і не купиш, а є книжки - як хочеться купити або навіть потрібно купити, але змушений часто це робити без перегляду хоч якогось контенту. Гугл може дати можливість віртуального швидкого перегляду книжки перед купівлею, - наче ви в справжньому магазині.
Подобається також можливість створювати власну бібліотеку. Або вставляти фрейв сторінку із книжкою :)
Maven допоможе!
Вирішив записати декілька корисних речей, з якими доводиться мати часто справу користувачу мавена в повсякденному житті, наприклад, мені:
Список не повний, буду його розширювати як тільки буду згадувати та знаходити нові тіпси.
- Запуск із ключиком
-oкаже мавену працювати в оффлайновому режимі, а це інколи економить час якого немає. В цьому випадку мавен шукає всі бібліотеки та плагіни в локальному репозиторії і навіть не пробує стукатися до центральних репозиторіїв за апдейтом тощо. Також корисно з повільним та нестабільним інтернетом. - Проперті
maven.test.skipпоможе виконати компіляцію та збірку проекту без виконання тестів. Корисно, коли середовище для тестування не готово або ж з тестами все ок, а проблема з якимись плагінами або просто треба зібрати проект, щоб викласти десь. Може запускатися таким чином:mvn install -Dmaven.test.skip=true. - Файл
MVN_HOME/conf/settings.xmlмістить ряд корисних настройок. Однією з них єlocalRepository, за допомогою якої можна вказати шлях до репозиторія десь на диску відмінному від C:. Користувачі windows часто форматують C: і рідко бекаплять репозиторій. Правильний шлях може зберегти чимало часу при перевстановленні windows наступного разу. - Якщо використовується плагін мавена для генерації
javadocдля проекта з декількома модулями, то може бути дуже корисно виконати агрегації згенерованої документації, а для цього можна скористатися властивістюaggregate, наприклад:
<plugin>
<artifactId>maven-javadoc-plugin>/artifactId>
<configuration>
<aggregate>true</aggregate>
</configuration>
</plugin>
Список не повний, буду його розширювати як тільки буду згадувати та знаходити нові тіпси.
A Few Maven Tips
Decided to write some useful things, which often helps in everyday life to Maven user, like me:
- The command line argument
-osaid to Maven to work in offline mode and this sometimes saves time. In this case, maven is lookіng for all the libraries and plugins in the local repository and do not even tries to ping central repositories for update. Also useful with slow and unstable Internet connection. - Property
maven.test.skiphelps to perform project compilation without running test cases. Could be useful when the environment is not yet ready for testing or all tests green. Run command in next format:mvn install -Dmaven.test.skip=true. - File
MVN_HOME/conf/settings.xmlcontains a number of useful settings. One of them islocalRepository, through which you can specify the repository somewhere on the disk D: etc. Windows users oftenly format drive C: and rarely backups local Maven repository. Correct value for this setting can save a lot of time after re-installing windows next time. - If you are using Maven plugin to generate Javadoc for a project with multiple modules, it can be very useful to perform the aggregation of generated documentation. In this case use property
aggregate, for example:
<plugin>
<artifactId>maven-javadoc-plugin>/artifactId>
<configuration>
<aggregate>true</aggregate>
</configuration>
</plugin>
The list is not complete, it will expand as soon as I remember or find new tips.
Динамічний репорт за допомогою JasperReports
На проекті, над яким я працював десь рік тому, постала задача виконувати динамічну генерацію друкованої версії звіту. На проекті для генерації звітів використовувався JasperReports.
Отже, постали наступні питання
1. Як виконувати динамічну генерацію звіту:
- чи є для цього API,
- чи все-таки генерувати XML, а потім його компілювати?
2. Як передавати дані?
При виборі способу генерації динамічного звіту я вирішив використати перший варіант - працювати із API JasperReports для формування представлення звіту. Ідея генерувати XML в коді мені не дуже подобалася, тому що в цьому випадку код виглядав для мене заплутаним. Крім того, зміна версії бібліотеки могла привести до помилки, яку би було тяжко визначити. З API ситуація була інакшою: досягалася непогана чистота коду із можливістю абстрагування для різних видів звітів. Та й при компіляції можна було визначити сумісність використовуваного API із версією бібліотеки.
Дивно, але на той час мене чомусь не осягнула ідея використовувати JSP, Velocity чи FreeMarker для генерації шаблону звіту. Мені здається, що на даний момент я би використав саме цей спосіб.
Тут дуже знадобився такий клас як JasperDesign та набір класів сімейства Design. До класів сімейства Design відносяться:
Створювати репорти динамічно просто і зручно. Але це є виключною ситуацією, оскільки завжди можна скористатися вашим олюбленим редактором XML або ж iReport.
Мені свого часу довелося створити чимало репортів за допомогою Jasper. Більшість шаблонів створювалися в редакторі XML, чимало динамічних створювалися в коді і могли поєднювати ще декілька динамічних репортів, інші просто накидувалися швидкоруч в iReport.
Для тих, кому цікаво, хочу привести декілька прикладів використання API JasperReport.
Створення елементів звіту:
Ініціалізація звіту:
Заповнення звіту:
Компіляція звіту:
Використання отриманого
Отже, постали наступні питання
1. Як виконувати динамічну генерацію звіту:
- чи є для цього API,
- чи все-таки генерувати XML, а потім його компілювати?
2. Як передавати дані?
При виборі способу генерації динамічного звіту я вирішив використати перший варіант - працювати із API JasperReports для формування представлення звіту. Ідея генерувати XML в коді мені не дуже подобалася, тому що в цьому випадку код виглядав для мене заплутаним. Крім того, зміна версії бібліотеки могла привести до помилки, яку би було тяжко визначити. З API ситуація була інакшою: досягалася непогана чистота коду із можливістю абстрагування для різних видів звітів. Та й при компіляції можна було визначити сумісність використовуваного API із версією бібліотеки.
Дивно, але на той час мене чомусь не осягнула ідея використовувати JSP, Velocity чи FreeMarker для генерації шаблону звіту. Мені здається, що на даний момент я би використав саме цей спосіб.
Тут дуже знадобився такий клас як JasperDesign та набір класів сімейства Design. До класів сімейства Design відносяться:
- JRDesignField
- JRDesignStyle
- JRDesignStaticText
- JRDesignTextField
- JRDesignExpression
- JRDesignBand
- і багато інших.
Створювати репорти динамічно просто і зручно. Але це є виключною ситуацією, оскільки завжди можна скористатися вашим олюбленим редактором XML або ж iReport.
Мені свого часу довелося створити чимало репортів за допомогою Jasper. Більшість шаблонів створювалися в редакторі XML, чимало динамічних створювалися в коді і могли поєднювати ще декілька динамічних репортів, інші просто накидувалися швидкоруч в iReport.
Для тих, кому цікаво, хочу привести декілька прикладів використання API JasperReport.
Створення елементів звіту:
public static JRStyle getDefaultStyle() {
JRDesignStyle style = new JRDesignStyle();
style.setName("defaultStyle");
style.setDefault(true);
style.setFontName("Arial");
style.setFontSize(8);
style.setPdfFontName("/TTF/arial.ttf");
style.setPdfEncoding("Identity-H");
style.setPdfEmbedded(true);
return style;
}
public static JRStyle getHeadStyle() {
JRDesignStyle style = new JRDesignStyle();
style.setName("headStyle");
style.setDefault(true);
style.setFontName("Arial");
style.setFontSize(8);
style.setBold(true);
style.setPdfFontName("/TTF/arial.ttf");
style.setPdfEncoding("Identity-H");
style.setPdfEmbedded(true);
return style;
}
public static JRDesignElement staticTextElement(String text,
int height, int width,
int x, int y,
boolean headStyle) {
JRDesignStaticText staticText = new JRDesignStaticText();
staticText.setText(text);
staticText.setWidth(width);
staticText.setHeight(height);
staticText.setX(x);
staticText.setY(y);
staticText.setBorder(JRGraphicElement.PEN_THIN);
if (headStyle) staticText.setStyle(getHeadStyle());
return staticText;
}
public static JRDesignElement textFieldElement(String text, Class type,
int height, int width,
int x, int y,
boolean headStyle) {
JRDesignTextField textField = new JRDesignTextField();
textField.setWidth(width);
textField.setHeight(height);
textField.setX(x);
textField.setY(y);
textField.setBorder(JRGraphicElement.PEN_THIN);
if (headStyle) textField.setStyle(getHeadStyle());
JRDesignExpression expression = new JRDesignExpression();
expression.setText(text);
expression.setValueClassName(type.getName());
textField.setExpression(expression);
return textField;
}
public static JRDesignElement textFieldElement(Property property,
int height, int width,
int x, int y,
boolean headStyle) {
JRDesignTextField textField = new JRDesignTextField();
textField.setWidth(width);
textField.setHeight(height);
textField.setX(x);
textField.setY(y);
textField.setBorder(JRGraphicElement.PEN_THIN);
if (headStyle) textField.setStyle(getHeadStyle());
JRDesignExpression expression = new JRDesignExpression();
expression.setValueClassName(property.getType().getName());
if (property instanceof Column) {
expression.addFieldChunk(property.getName());
}
else {
expression.addParameterChunk(property.getName());
}
textField.setExpression(expression);
return textField;
}
Ініціалізація звіту:
JasperDesign reportDesign = new JasperDesign();
reportDesign.setName(context.getDataResult().getDataReport().reportType().getReportName());
reportDesign.setOrientation(JasperDesign.ORIENTATION_LANDSCAPE);
reportDesign.setIgnorePagination(true);
reportDesign.setTopMargin(5);
reportDesign.setBottomMargin(5);
reportDesign.setLeftMargin(5);
reportDesign.setRightMargin(5);
reportDesign.setWhenNoDataType(JasperDesign.WHEN_NO_DATA_TYPE_NO_PAGES);
reportDesign.addImport("java.lang.*");
reportDesign.addImport("java.math.*");
reportDesign.addImport("java.util.*");
reportDesign.addImport("net.sf.jasperreports.engine.*");
reportDesign.addImport("net.sf.jasperreports.engine.data.*");
reportDesign.addStyle(getDefaultStyle());
reportDesign.addStyle(getHeadStyle());
Заповнення звіту:
JRDesignBand rootBand = new JRDesignBand();
rootBand.setHeight(40);
rootBand.setSplitAllowed(true);
reportDesign.setDetail(rootBand); // could be setTitle() or setSummary() etc.
rootBand.addElement(textFieldElement("Details", String.class,
height, 120, currentX, currentY, false));
Компіляція звіту:
JasperReport compileReport(JasperDesign reportDesign) throws ReportException {
try {
log.info("Compiling report...");
return JasperCompileManager.compileReport(reportDesign);
}
catch (Exception e) {
log.error("Error to compile report, cause:", e);
throw new ReportException("Error to compile report!", e);
}
}
Використання отриманого
JasperReport:
JasperDesign reportDesign = new JasperDesign();
//
// preparing and filling report design goes here...
//
JasperReport jasperReport = compileReport(jasperDesign);
JasperPrint jasperPrint = JasperFillManager.fillReport(
jasperReport, prepareParameters(), prepareDataSource());
yUML
Just linked yUML to my blog. I like that service.
There are also few articles about it here.
There are next few yUML samples:
And now Scruffy variant:
Looks great, isn't it?
There are also few articles about it here.
There are next few yUML samples:
[Document]<0..*-1[DocumentTemplate],[DocumentTemplate]-^[Template]
[DocumentTemplate]-^[Template],[ReportTemplate]-^[Template|-name;-author;-location|open();save();remove()],[FigureTemplate]-^[Template]
[Administrator]-(Create Template),[Administrator]-(Create Document)
And now Scruffy variant:
[Document]<0..*-1[DocumentTemplate],[DocumentTemplate]-^[Template],[ReportTemplate]-^[Template],[FigureTemplate]-^[Template],[Template]->[Author|firstName;lastName],[Template]->[Resource|fileName;type;version]
[Ruslan]-(Create Article), [Ruslan]-(Edit Article),
[Ruslan]-(Write Comments)
[Ruslan]-(Write Comments)
Looks great, isn't it?
Linus about Git
Перше серйозне знайомство з Git було в мене після перегляду відео презентації Лінусом Торвальдсом, на якій він розсказував наскільки Git крутий, а майже все інше близьке до лайна. Як на мене, занадто він впевнено про це заявляв, але і мені Git сподобався тоже.
Відео було на англійській мові, але не давно знайшов переклад цього відео. Точніше, переклад слів Торвальдса.
http://lib.custis.ru/index.php/Линус_Торвальдс_о_GIT_на_Google_Talks
Відео було на англійській мові, але не давно знайшов переклад цього відео. Точніше, переклад слів Торвальдса.
http://lib.custis.ru/index.php/Линус_Торвальдс_о_GIT_на_Google_Talks
Git and Subversion works together
I like the idea to use Subversion central repository with a Git local "stub" repository. With having local Git repository I have access to the all history of some branch or trunk, as I have a local copy of Subversion repository. Local commits and easy branching is a big plush for me too.
Most of us are working with Subversion repositories, as they are wide used and popular nowadays. These tool gives us advantages to work with branches, setup security, transaction commits and many more. While Git proposes easy and low cost branching, decentralized storing and low coupling developers interaction. Yes, I said low coupling, as 2 developers that are working on the same thing in parallel now are able to synchronize code locally, without central repository.
I don't know what is your experience with merging branches using Subversion, but for me it's a hell. With a few different branches, that are ready to be merged into trunk but is not, because "we don't need it in trunk now, but maybe in 2 weeks we will". Sometimes merging takes the same time as new feature development.
Now Git can help us with it, as has new operation
It's currently working fine on Linux, but you should be ready to get some unpredictable behavior on Windows. Expecting that with 1.6.3 and latest versions git-svn will work much better that with Git-1.6.2.2-preview20090408.
Most of us are working with Subversion repositories, as they are wide used and popular nowadays. These tool gives us advantages to work with branches, setup security, transaction commits and many more. While Git proposes easy and low cost branching, decentralized storing and low coupling developers interaction. Yes, I said low coupling, as 2 developers that are working on the same thing in parallel now are able to synchronize code locally, without central repository.
I don't know what is your experience with merging branches using Subversion, but for me it's a hell. With a few different branches, that are ready to be merged into trunk but is not, because "we don't need it in trunk now, but maybe in 2 weeks we will". Sometimes merging takes the same time as new feature development.
Now Git can help us with it, as has new operation
git svn.It's currently working fine on Linux, but you should be ready to get some unpredictable behavior on Windows. Expecting that with 1.6.3 and latest versions git-svn will work much better that with Git-1.6.2.2-preview20090408.
Git Advantages
Побавився сьогодні трохи з Git. Досі я в основному працював з SVN, і тільки із централізованими системами контролю версій.
В Git знайшов кілька цікавих речей, які мені ясно сподобалися, а саме:
Це тільки декілька можливостей. Мені вони здалися найкориснішими.
Звичайно, частину з них можна добитися і від SVN, але для цього треба докласти чимало часу, а інколи і грошей.
P.S.
Знайшов гарну статтю про переваги Git над SVN: http://git.or.cz/gitwiki/GitSvnComparsion і навпаки.
В Git знайшов кілька цікавих речей, які мені ясно сподобалися, а саме:
- Розприділені SCM дозволяють мати локальний репозиторій, з яким працювати є набагато зручніше. Адже він
завжди зі мною, я можу виконувати кілька незалежних комітів, які просто потім відправляти в публічний репозиторій, коли є необхідність і можливість. Розприділені репозиторії дозволять мені також синхронізуватися з іншими програмістами без необхідності внесення змін в публічний репозиторій. - Можливість створювати декілька commit lists, для того щоб комітити різні зміни із різними коментарями. Дуже корисно для підтримки порядку.
- Можливість вибудовувати ієрархію репозиторіїв. Розприділення відповідальності між програмістами тепер може бути на рівні окремого репозиторію. Річ цікава і корисна, і якщо коли-не-будь доводилося працювати із репозиторіями, що знаходяться на іншому кінці світу, заховані за тучою файерволів і взагалі частенько є недоступними, тоді мене можна буде зрозуміти.
- Можливість вносити зміни в історію комітів, наприклад, видалити зайвий файл або підкорегувати коментар.
- Зручна та швидка робота із бренчами.
- Message при коміті є обов'язковим.
- Зручна робота із git в консолі.
- Нема необхідності виконувати бекапи публічного репозиторію, якщо є декілька програмістів, що мають його локальну копію.
Це тільки декілька можливостей. Мені вони здалися найкориснішими.
Звичайно, частину з них можна добитися і від SVN, але для цього треба докласти чимало часу, а інколи і грошей.
P.S.
Знайшов гарну статтю про переваги Git над SVN: http://git.or.cz/gitwiki/GitSvnComparsion і навпаки.
ClearFont setup tool for WinXP
Не великий секрет - я користуюся Windows XP і наразі для мене це найкраща ОС. А заради відчуття красивого вмикаю я згладжування шрифтів ClearType.
Ось тільки кілька місяців тому змушений був відмовитися, адже на новому моніторі це згладжування виглядало просто огидно. Але не так давно знайшов прикольну тулзу від майкрософта http://www.microsoft.com/typography/ClearTypePowerToy.mspx.
Після вельми простої конфігурації, я отримав хорошу якість згладжування шрифтів.
Ось тільки кілька місяців тому змушений був відмовитися, адже на новому моніторі це згладжування виглядало просто огидно. Але не так давно знайшов прикольну тулзу від майкрософта http://www.microsoft.com/typography/ClearTypePowerToy.mspx.
Після вельми простої конфігурації, я отримав хорошу якість згладжування шрифтів.
System.nanoTime() and measurements
I'm still using simple
But for some algorithms, especially in development environment
But, everyone will say that it is not important what way of implementation you'll choose if difference is less than 1ms. It doesn't matter. And they will be right. In this case it doesn't matter what is faster, even if production amount of data is much more than testing amount of data and this may affect execution time significantly. Algorithm does matter.
It always depends on algorithm!
System.currentTimeMillis() when need to test performance of some part of code. It's fast and easy to use, especially to profile some algorithm while coding; performance still is an important measure used to choose between few algorithms or choose the best way how to implement algorithm.But for some algorithms, especially in development environment
System.currentTimeMillis() doesn't give any valuable results as it's hard to choose between 0ms and 0ms returned for both algorithms :) System.nanoTime() can used in such situations. It helps to get precise measurement of code execution time.But, everyone will say that it is not important what way of implementation you'll choose if difference is less than 1ms. It doesn't matter. And they will be right. In this case it doesn't matter what is faster, even if production amount of data is much more than testing amount of data and this may affect execution time significantly. Algorithm does matter.
It always depends on algorithm!
JBoss Richfaces Refcard is ready for free download
DZone provides a list of free to download and use refcards for different technologies and tools (like IDE). Few days ago new refcard was release, and it's about JBoss Richfaces. You may download it here http://refcardz.dzone.com/refcardz/richfaces.
At page http://refcardz.dzone.com/ you may download more and more refcards for yourself. Some time ago I've downloaded for Eclipse, my favorite IDE IntellijIDEA, Spring, Groovy etc. And now downoloading JBoss Richfaces refcard too.
At page http://refcardz.dzone.com/ you may download more and more refcards for yourself. Some time ago I've downloaded for Eclipse, my favorite IDE IntellijIDEA, Spring, Groovy etc. And now downoloading JBoss Richfaces refcard too.
Presentations and articles about scalable software architecture
Last week was searching for interesting articles and presentations with samples of scalable and failure tolerant architecture. As result, my bookmarks increased with a number of new links to articles and videos.
Articles:
Videos & presentations:
Articles:
- Scalability Principles
- SEDA
- Large codebase organization with Spring
- Building Scalability and Achieving Performance: A Virtual Panel
- Scalability Worst Practices
- Shard Lessons
- Asynchronous Architectures [4]
- Thoughts on Development
- Hitting the scalability wall - Amdahl's Law
- 10 Lessons in Scalability from MySpace
- Twitter as a scalability case study
Videos & presentations:
- Randy Shoup on eBay's Architectural Principles
- Architecture Evaluation in Practice
- Availability & Consistency
- Architecting for Latency
- The Design and Architecture of InfoQ
- Architecture Quality: Operational Manageability
- How to scale your web app
- Behind the Scenes at MySpace.com
- Scaling Twitter
Cловники в предметній області
Словники предметної області займають вельми важливе місце при проектуванні та розробці програмного забезпечення. Не менш частіше використовуються словники в предметній області. В даному випадку, словниками можуть виступати невеликі набори даних в стилі ключ-значення, або більш складні, де кожному ключу відповідає набір значень. Прикладів таких словників є безліч, наприклад, словник країн, словник типів кредитних карточок, словник пріоритетів задач, і більш складніші словники матеріалів та продукції (за окремими вийнятками) тощо.
Ця стаття розповідає про моє бачення такого "патерна" як Словник. Важливо визначитися, що саме слід вважати словником в предметній області.
Словник – це набір термінів пов’язаних між собою певною областю використання, які проте рідко змінюються. Частіше всього, словники використовуються, для того, щоб надати користувачам вибір значень з певної множити, наприклад, країну проживання, стать, посаду тощо.
Словники складаються з записів, які собою являють пару ключ-значення. В залежності від значення словники бувають простими та складними. Простий словник, це коли певному ключу відповідає одне значення, а складний словник – ключу відповідає набір значення. Наприклад, якщо коду країни відповідає тільки назва цієї країни, то цей словник є простим, де ключем виступає код країни. Прикладом складного словника є словник матеріалів, де коду товару відповідає його назва, вартість, країна виробник, маса тощо.
Складні словники можуть бути складеними. Складеним словником називається такий, в якого одне із значень є елементом іншого словниками. Наприклад, дано складний словник країн, в якому певному коду відповідають назва та код типу країни (республіка, федерація, королівство тощо). Код типу країни вказує на словник типів країн, таким чином словник країни можна вважати складеним та залежним від словника типів країн.
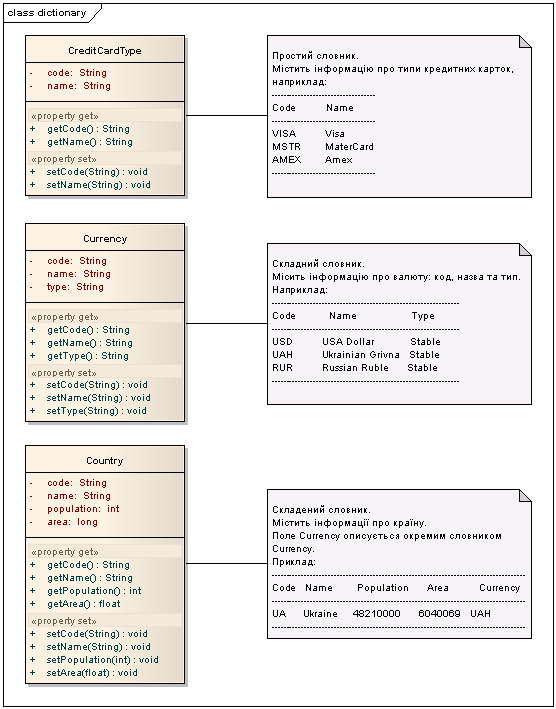
Рис 1 – Різні типи словників.
Словники часто використовують при розробці програмного забезпечення, адже дають можливість групувати набори даних в окремі групи, використовувати їх в групах та асоціювати певне значення з групою. В предметної області певний набір даних може бути словником, якщо він не виступає центральним в даній предметній області. Словники повинні залишатися максимально спрощеним та піддававтися мінімальним змінам в процесі використання, в той час як центральні сутності предметної можуть бути дуже складними та змінювати часто.
Чим складніший словник, тим більше програмний продукт залежить від нього. Словники можуть з часом переростати на повноцінні набори даних. При цьому збільшується або їх складності або кількість даних.
Зі словників часто починається проектування та кодування програм, вони є об’єктом перевикористання. Якщо використовувати необхідні словники спроектовані та закодовані на попередніх проектах, то можна скоротити час на написання нових проектів. Розроблений словник може виступати незалежним компонентом, але подібні компоненти буває тяжко спроектувати, адже вони вимагають гнучкості в роботі, а також тісної залежності від них іншого коду.
Існує кілька способів зберігання даних словників: набори констант, енумерації, файли, база даних тощо. Використання констант та енумерації для зберігання елементів словника пожуть значно покращити процес кодувати та збільшити читабельність коду, але при цьому частіше всього ми втрачаємо можливість швидкої зміни «захардкодженого» набору даних. Звичайно, словник статей, може бути спокійно закодований у вигляді енумерації, але словник країн ні. Те, що словники змінюються рідко не значить, що вони ніколи не міняються. В окремих випадках є необхідність добавити нові елементи або виконати користування існуючих, і в залежності від типу програми, найкращими будуть тут зберігання словників у файлах та базах даних.
Ще однією хорошою практикою є змістовні ключі словників. Простіше працювати та підтримувати в роботі словники, що містять ключі, які легко зрозуміти та отримати інформацію про сам елемент словника. Цього тяжко досягнути якщо використовувати числові ідентифікатори. Наприклад, для словника типів кредитних карточок ключі VISA, MSTR, AMEX тощо зручніше використовувати, ніж, наприклад, 1, 2, 3. У випадку використання бази даних для зберігання словників також простіше писати запити.
Оскільки словники містять невеликі набори даних і в основному рідко змінюються, то вони частіше легко піддаються кешуванню. Але тут слід не забувати, що словники теж можуть міняти, тому програма повинна підтримувати або можливість обновити дані в кеші або виконати інвалідацію кеша або ж увімкнути підтримку дати закінчення терміни дії кешу, після якого нові дані будуть знов закешовані.
Для зберігання та використання словників можна також використовувати і інші способи. Наприклад, якщо використовується MySQL, то для роботи із таблицями з словниками можна використвувати MyISAM engine, адже він найкраще підходить для даних, що рідко змінуюються, але частіше зчитуються. Таблиці із словниками частіше піддаються повному кешуванню СУБД, а використання сладених індексів на всі колонки БД може взагалі позбавити необхідность у фізичному вводі-виводі. Збереження словників у базі даних та використання зовнішніх ключів покращує цілісність даних, і знову ж таки, не сильно впливає на ресурси для виконання запитів.
Ця стаття розповідає про моє бачення такого "патерна" як Словник. Важливо визначитися, що саме слід вважати словником в предметній області.
Словник – це набір термінів пов’язаних між собою певною областю використання, які проте рідко змінюються. Частіше всього, словники використовуються, для того, щоб надати користувачам вибір значень з певної множити, наприклад, країну проживання, стать, посаду тощо.
Словники складаються з записів, які собою являють пару ключ-значення. В залежності від значення словники бувають простими та складними. Простий словник, це коли певному ключу відповідає одне значення, а складний словник – ключу відповідає набір значення. Наприклад, якщо коду країни відповідає тільки назва цієї країни, то цей словник є простим, де ключем виступає код країни. Прикладом складного словника є словник матеріалів, де коду товару відповідає його назва, вартість, країна виробник, маса тощо.
Складні словники можуть бути складеними. Складеним словником називається такий, в якого одне із значень є елементом іншого словниками. Наприклад, дано складний словник країн, в якому певному коду відповідають назва та код типу країни (республіка, федерація, королівство тощо). Код типу країни вказує на словник типів країн, таким чином словник країни можна вважати складеним та залежним від словника типів країн.
Рис 1 – Різні типи словників.
Словники часто використовують при розробці програмного забезпечення, адже дають можливість групувати набори даних в окремі групи, використовувати їх в групах та асоціювати певне значення з групою. В предметної області певний набір даних може бути словником, якщо він не виступає центральним в даній предметній області. Словники повинні залишатися максимально спрощеним та піддававтися мінімальним змінам в процесі використання, в той час як центральні сутності предметної можуть бути дуже складними та змінювати часто.
Чим складніший словник, тим більше програмний продукт залежить від нього. Словники можуть з часом переростати на повноцінні набори даних. При цьому збільшується або їх складності або кількість даних.
Зі словників часто починається проектування та кодування програм, вони є об’єктом перевикористання. Якщо використовувати необхідні словники спроектовані та закодовані на попередніх проектах, то можна скоротити час на написання нових проектів. Розроблений словник може виступати незалежним компонентом, але подібні компоненти буває тяжко спроектувати, адже вони вимагають гнучкості в роботі, а також тісної залежності від них іншого коду.
Існує кілька способів зберігання даних словників: набори констант, енумерації, файли, база даних тощо. Використання констант та енумерації для зберігання елементів словника пожуть значно покращити процес кодувати та збільшити читабельність коду, але при цьому частіше всього ми втрачаємо можливість швидкої зміни «захардкодженого» набору даних. Звичайно, словник статей, може бути спокійно закодований у вигляді енумерації, але словник країн ні. Те, що словники змінюються рідко не значить, що вони ніколи не міняються. В окремих випадках є необхідність добавити нові елементи або виконати користування існуючих, і в залежності від типу програми, найкращими будуть тут зберігання словників у файлах та базах даних.
Ще однією хорошою практикою є змістовні ключі словників. Простіше працювати та підтримувати в роботі словники, що містять ключі, які легко зрозуміти та отримати інформацію про сам елемент словника. Цього тяжко досягнути якщо використовувати числові ідентифікатори. Наприклад, для словника типів кредитних карточок ключі VISA, MSTR, AMEX тощо зручніше використовувати, ніж, наприклад, 1, 2, 3. У випадку використання бази даних для зберігання словників також простіше писати запити.
Оскільки словники містять невеликі набори даних і в основному рідко змінюються, то вони частіше легко піддаються кешуванню. Але тут слід не забувати, що словники теж можуть міняти, тому програма повинна підтримувати або можливість обновити дані в кеші або виконати інвалідацію кеша або ж увімкнути підтримку дати закінчення терміни дії кешу, після якого нові дані будуть знов закешовані.
Для зберігання та використання словників можна також використовувати і інші способи. Наприклад, якщо використовується MySQL, то для роботи із таблицями з словниками можна використвувати MyISAM engine, адже він найкраще підходить для даних, що рідко змінуюються, але частіше зчитуються. Таблиці із словниками частіше піддаються повному кешуванню СУБД, а використання сладених індексів на всі колонки БД може взагалі позбавити необхідность у фізичному вводі-виводі. Збереження словників у базі даних та використання зовнішніх ключів покращує цілісність даних, і знову ж таки, не сильно впливає на ресурси для виконання запитів.
Spring MVC and RESTful web service.
This article is a result of my experience on building small RESTful web service using SpringMVC 2.5. Web service is simple, it supports only few operations, most of them just retrieves data and sends back it in XML.
Well, the task is simple enough:
As web service is build with REST philosophy, than we need to support processing of GET, POST (well, for me it's enough) requests and return data as XML or JSON. Spring MVC as well others REST web service frameworks and API help with this too. So, what's next?
As application is build with Spring 2.5, it was the best to have some framework for building REST web service easily and easily to integrate it with Spring. Not a secret, that Spring MVC integrates with Spring better that any other web framework or REST web service framework (hm, maybe it's because it is build on Spring). Well, this is cons for using Spring MVC and it is good, but truly - this not enough yet.
Yet one requirement: SOAP web service could be added later. And if it could be added than (in most cases) it will be added. This is important, very important, because we want to build easy-to-extend software. And in case of SOAP WS I prefer to use Spring WS, that is well integrated with Spring MVC. Need also to take into consideration that some REST web service frameworks hardly integrates with Spring MVC or wanted to process all requests. That is a great pros for using Spring MVC.
You may understand what I'm implying. Yes, Spring MVC will be used to build RESTful web service.
The main goals of architecture are:
Next decisions were made:
The main result of made decisions & rules is request processing lifecycle, that consists of next few phases:
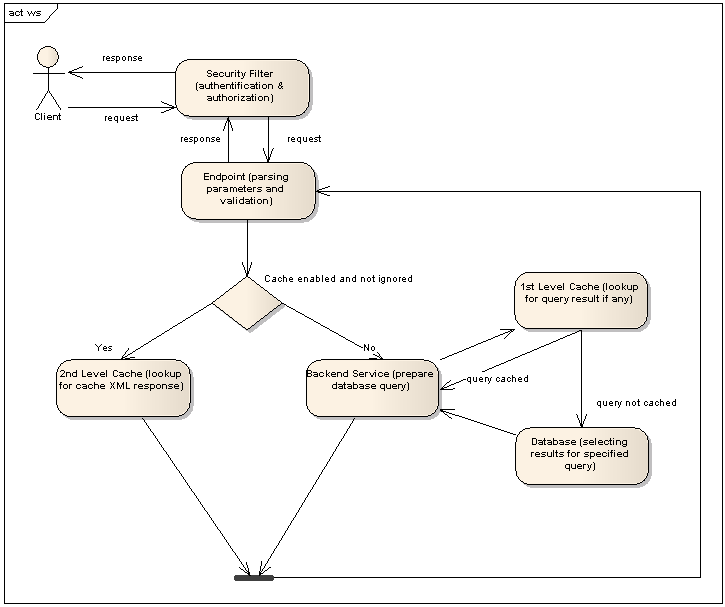
So, if the request response is cached in 2nd or 1st cache levels, than response will be generated without hitting database. In my development environment caching helps to increase performance up to 1500%. In production this number is less - just 300-500%. Still these is very well.
This lifecycle helps to build a scheme of responsibilities and modules. Later each responsibility could be processed by own server or a set of servers.

Spring 2.5 gave us possibility to use annotations as for declaring services as for declaring SpringMVC controllers. Spring's annotations
Ofcourse, hardcoding of URLs in annotations looks as not the best way for building flexible and configurable application. But, this is quite pardonable, because we will use UrlRewriteFilter. UrlRewriteFilter is very useful tool, as it will helps to rewrite URLs, get parameters from URL and do other interesting things. But for our the most important are next 2 features:
Lets look how we could use this features:
Let we have RESTful web service that returns XML with information with specified by id book. Web service clients could get this information by requesting url
http://ourservice.com/ws/rest/book/{bookId} (e.g. http://ourservice.com/ws/rest/book/12). Our application should handle this call and the information about book wit specified id.
Here is our web service controller:
Code is very simple, but it's good as for sample.
So, we have controller that processes all GET requests for
This endpoint controller can't be default process web service request. To redirect web service client request to our endpoint we will use UrlRewriteFilter
so request for resource
That's about all for now. The story looks to long. Most of us do not have enough time to read long articles :)
Well, the task is simple enough:
- build secured web service for mostly getting and sometimes posting data;
- REST interface is required
- but SOAP could be added later (I think that if you build SOAP web service you should wait that you'll need to provide REST API for this web service too and vise versa).
As web service is build with REST philosophy, than we need to support processing of GET, POST (well, for me it's enough) requests and return data as XML or JSON. Spring MVC as well others REST web service frameworks and API help with this too. So, what's next?
As application is build with Spring 2.5, it was the best to have some framework for building REST web service easily and easily to integrate it with Spring. Not a secret, that Spring MVC integrates with Spring better that any other web framework or REST web service framework (hm, maybe it's because it is build on Spring). Well, this is cons for using Spring MVC and it is good, but truly - this not enough yet.
Yet one requirement: SOAP web service could be added later. And if it could be added than (in most cases) it will be added. This is important, very important, because we want to build easy-to-extend software. And in case of SOAP WS I prefer to use Spring WS, that is well integrated with Spring MVC. Need also to take into consideration that some REST web service frameworks hardly integrates with Spring MVC or wanted to process all requests. That is a great pros for using Spring MVC.
You may understand what I'm implying. Yes, Spring MVC will be used to build RESTful web service.
Architecture
The main goals of architecture are:
- be scalable (not to much, but enough to process thousands of requests per hour)
- be extendable (SOAP must be easy to add)
- do what is required and nothing more
Next decisions were made:
- request should be stateless
- each request should be processed as quick as possible
- there will be 2 levels of caching: one cache for entities and queries (used by web service backend service), and another cache for rendered XML response (used by web service endpoint).
- everything that could be changed is configured through simple XML configuration (i.e. cache configuration, security configuration, business logic configuration etc.)
The main result of made decisions & rules is request processing lifecycle, that consists of next few phases:
- Authentification & Authorization (security filter)
- Getting request parameters. Web service endpoint (in our case it is SpringMVC controller) parses request parameters and validates them.
- If everything is okay than it tries to get XML response from cache and sends it as response to the client. This step is optional and is processed only if cache is enabled and client does not specify request as such that ignores cache.
- Endpoint determines the appropriate WebService backend service and run it and get results.
- Endpoint converts results into XML, prepare response and stores it at cache (if cache is enabled). After the XML response is send back to client.
So, if the request response is cached in 2nd or 1st cache levels, than response will be generated without hitting database. In my development environment caching helps to increase performance up to 1500%. In production this number is less - just 300-500%. Still these is very well.
This lifecycle helps to build a scheme of responsibilities and modules. Later each responsibility could be processed by own server or a set of servers.
Simple implemenation
Spring 2.5 gave us possibility to use annotations as for declaring services as for declaring SpringMVC controllers. Spring's annotations
Controller, RequestMapping, RequestParam and flexible politic on request handle method parameters gives us brilliant instrument for building web service endpoint.Ofcourse, hardcoding of URLs in annotations looks as not the best way for building flexible and configurable application. But, this is quite pardonable, because we will use UrlRewriteFilter. UrlRewriteFilter is very useful tool, as it will helps to rewrite URLs, get parameters from URL and do other interesting things. But for our the most important are next 2 features:
- flexibility while mapping external URLs (used by users) to internal URLS (processed by endpoint controllers)
- possibility to catch parameters from URL, e.g. http://example.com/book/edit/12 ->
http://exampl.com/book/edit?boodId=12 etc.
Lets look how we could use this features:
Let we have RESTful web service that returns XML with information with specified by id book. Web service clients could get this information by requesting url
http://ourservice.com/ws/rest/book/{bookId} (e.g. http://ourservice.com/ws/rest/book/12). Our application should handle this call and the information about book wit specified id.
Here is our web service controller:
@Controller
public class WebServiceEndpoint {
@Autowired
private BookService bookService;
@RequestMapping(value = "webservice/book", methods = RequestMethod.GET)
public ModelAndView getBook(@RequestParam(name="bookID", required=true)int bookId, Map<String, Object> model) {
model.put("book", bookService.getBookById(bookId));
return new ModelAndView("template/ws/bookInfo", model);
}
}
Code is very simple, but it's good as for sample.
So, we have controller that processes all GET requests for
'webservice/book' resource, that should have request parameter of type integer with name 'bookID'. Endpoint just call backend service, gets information about book, put it to model map and return the ModelAndView instance with simple template that will be rendered and returned to client. This endpoint controller can't be default process web service request. To redirect web service client request to our endpoint we will use UrlRewriteFilter
<rule>
<from>^/ws/rest/book/[0-9]+$</from>
<to>/webservice/book?bookID=$1</to>
</rule>
so request for resource
http://ourservice.com/ws/rest/book/12 will be rewrited by filter to http://ourservice.com/webservice/book?bookID=12.That's about all for now. The story looks to long. Most of us do not have enough time to read long articles :)
Simple LRU cache implementation.
By this url can be found post about using
LinkedHashMap as LRU cache. Also, I've found such code with a direct link as comment in Apache Roller source code.
LinkedHashMap can be used as LRU cache because it supports ordering it's elements not only by insert order, but also by access-order. Also there is protected method removeEldestEntry in the LinkedHashMap that runs in the put() and putAll() methods. If that method returns true, than least recently inserted/accessed element will be removed.
You and your's sofware expansibility.
For a long time one of the scores of software I'm writing is expansibility. That's mean how fast, with minimum of changes, I can add new features or extend existed one.
I've made few notes and use them as often as possible. Here are they:
- Never or almost never requirements you are working on are complete. Even if customer told you that this is finish step and we stop work on it - that mean only - we stop the work for now and we may continue it after some time. And of course, that time may vary from few weeks to few month, so you may and you will forget the code. That's why always write comments to the code even if it is not yours!
- If you can extend the code you've write before - do it! If you need to get the list of some entities - use search engine if it exists. If search engine is not enough - extend it and use it. Be DRY principal follower!
- Write your code with one think: I will use it tomorrow too! That's mean that you should write quality code, well commented code and code that make everything you have now and a little bit more. Sure, this "a little bit more" should be result of your experience. If you don't have enough experience - use this too! Why? You'll get need experience much faster!
- Do code review! Often. Why? Because it increases the quality of your code and as result of software. And also you'll find your and yours colleagues weak and that is 50% of new experience. I like Atlassian experience with code reviewing for many tasks they do.
Simple, but important.
I've made few notes and use them as often as possible. Here are they:
- Never or almost never requirements you are working on are complete. Even if customer told you that this is finish step and we stop work on it - that mean only - we stop the work for now and we may continue it after some time. And of course, that time may vary from few weeks to few month, so you may and you will forget the code. That's why always write comments to the code even if it is not yours!
- If you can extend the code you've write before - do it! If you need to get the list of some entities - use search engine if it exists. If search engine is not enough - extend it and use it. Be DRY principal follower!
- Write your code with one think: I will use it tomorrow too! That's mean that you should write quality code, well commented code and code that make everything you have now and a little bit more. Sure, this "a little bit more" should be result of your experience. If you don't have enough experience - use this too! Why? You'll get need experience much faster!
- Do code review! Often. Why? Because it increases the quality of your code and as result of software. And also you'll find your and yours colleagues weak and that is 50% of new experience. I like Atlassian experience with code reviewing for many tasks they do.
Simple, but important.
Spring MVC + FreeMarker + Tiles 2
This is extended and translated into English version of my post Spring MVC + FreeMarker + Tiles 2. I've found that many are interested about the joint work of those frameworks.
Well, this article shows how to configure the Spring MVC application with Tiles 2 and FreeMarker. You may don't use the SpringMVC framework, and in this case you need to make by your hands all the configuration work that Spring MVC does for you.
As you may know, Freemarker is popular template engine write on Java and used by mostly by Java applications. Tiles 2 is also Java frameworks used to prepare document using one or more "tiles" - the parts that are defined separately but used to be generated at one document. For example, using tiles you can define site header/footer, news or post blocks at your site etc.
So, how did I get it working?
Simple!
In file
And here is the important part *-servlet.xml configuration:
Also show here the part of general.xml file where Tiles definitions are set up.:
Source code of
Source code of
Why we need those two classes? Simple enough. Class
And
Well, this article shows how to configure the Spring MVC application with Tiles 2 and FreeMarker. You may don't use the SpringMVC framework, and in this case you need to make by your hands all the configuration work that Spring MVC does for you.
As you may know, Freemarker is popular template engine write on Java and used by mostly by Java applications. Tiles 2 is also Java frameworks used to prepare document using one or more "tiles" - the parts that are defined separately but used to be generated at one document. For example, using tiles you can define site header/footer, news or post blocks at your site etc.
So, how did I get it working?
Simple!
In file
web.xml add the freemarker configuration.
<servlet>
<servlet-name>pages</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>pages</servlet-name>
<url-pattern>*.page</url-pattern>
</servlet-mapping>
<servlet>
<servlet-name>freemarker</servlet-name>
<servlet-class>freemarker.ext.servlet.FreemarkerServlet</servlet-class>
<init-param>
<param-name>TemplatePath</param-name>
<param-value>/</param-value>
</init-param>
<init-param>
<param-name>NoCache</param-name>
<param-value>true</param-value>
</init-param>
<init-paramv
<param-name>ContentType</param-name>
<param-value>text/html</param-value>
</init-param>
....
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>freemarker</servlet-name>
<url-pattern>*.ftl</url-pattern>
</servlet-mapping>
And here is the important part *-servlet.xml configuration:
<!-- Tiles 2 configuration-->
<bean id="tilesConfigurer" class="org.springframework.web.servlet.view.tiles2.TilesConfigurer">
<property name="definitions">
<list>
<!-- the tiles configuration files are declared here -->
<value>/WEB-INF/defs/general.xml</value>
<value>/WEB-INF/defs/secure.xml</value>
</list>
</property>
</bean>
<bean id="tilesViewResolver" class="com.javaua.spring.integration.ext.ExtUrlBasedViewResolver">
<property name="viewClass" value="com.javaua.spring.integration.ext.ExtTilesView"/>
<property name="exposeSpringMacroModel" value="true"/>
</bean>
<bean id="viewResolver" class="org.springframework.web.servlet.view.freemarker.FreeMarkerViewResolver">
<property name="cache" value="true"/>
<property name="prefix" value=""/>
<property name="suffix" value=".ftl"/>
<!-- if you want to use the Spring FreeMarker macros, set this property to true -->
<property name="exposeSpringMacroHelpers" value="true"/>
</bean>
<!-- Controller that returns view = /layout/header -->
<bean name="/layout/header.page" class="com.javaua.HeaderController"/>
Also show here the part of general.xml file where Tiles definitions are set up.:
<definition name="home" extends="default">
<put-attribute name="title" value="Home Page"/>
<put-attribute name="body" value="/templates/home.ftl"/>
</definition>
<definition name="default" template="/templates/main.ftl">
<put-attribute name="header" value="/layout/header.page"/>
<put-attribute name="footer" value="/templates/layout/footer.ftl"/>
</definition>
<definition name="/layout/header" template="/templates/layout/header.ftl"/>
Source code of
com.javaua.spring.integration.ext.ExtUrlBasedViewResolver class:
import org.springframework.core.Ordered;
import org.springframework.web.servlet.View;
import org.springframework.web.servlet.view.AbstractUrlBasedView;
import org.springframework.web.servlet.view.UrlBasedViewResolver;
public class ExtUrlBasedViewResolver extends UrlBasedViewResolver implements Ordered {
private boolean exposeSpringMacroModel = false;
public void setExposeSpringMacroModel(boolean exposeSpringMacroModel) {
this.exposeSpringMacroModel = exposeSpringMacroModel;
}
protected View loadView(String viewName, Locale locale) throws Exception {
AbstractUrlBasedView view = buildView(viewName);
View viewObj = (View) getApplicationContext().getAutowireCapableBeanFactory().initializeBean(view, viewName);
if (viewObj instanceof ExtTilesView) {
ExtTilesView tilesView = (ExtTilesView) viewObj;
tilesView.setExposeSpringMacroModel(exposeSpringMacroModel);
}
return viewObj;
}
Source code of
com.javaua.spring.integration.ext.ExtTilesView class:
import org.springframework.web.servlet.view.tiles2.TilesView;
import org.springframework.web.servlet.view.AbstractTemplateView;
import org.springframework.web.servlet.support.RequestContext;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.ServletException;
import java.util.Map;
public class ExtTilesView extends TilesView {
private boolean exposeSpringMacroModel = false;
public void setExposeSpringMacroModel(boolean exposeSpringMacroModel) {
this.exposeSpringMacroModel = exposeSpringMacroModel;
}
@SuppressWarnings("unchecked")
protected final void renderMergedOutputModel(Map model, HttpServletRequest request,
HttpServletResponse response) throws Exception {
if (exposeSpringMacroModel) {
if (model.containsKey(AbstractTemplateView.SPRING_MACRO_REQUEST_CONTEXT_ATTRIBUTE)) {
throw new ServletException(
"Cannot expose bind macro helper '" +
AbstractTemplateView.SPRING_MACRO_REQUEST_CONTEXT_ATTRIBUTE +
"' because of an existing model object of the same name");
}
model.put(AbstractTemplateView.SPRING_MACRO_REQUEST_CONTEXT_ATTRIBUTE,
new RequestContext(request, getServletContext(), model));
}
super.renderMergedOutputModel(model, request, response);
}
}
Why we need those two classes? Simple enough. Class
ExtTilesView exposes Spring macro model which is required when using standard macros used to support work with Freemarker and Velocity typelate frameworks. And the class ExtUrlBasedViewResolver helps us to prevent view-not-found-error. Because, standard UrlBasedViewResolver is used for getting tiles view, it will throw an error when view with specified name is not found. In my case, I have two view resolvers and each will throw an error if view can't be found. And
FreeMarkerViewResolver will request for the file, while tiles requests just for XML definition. That's why I've ran the tiles view resolver as first one.GC and performance
Мабуть, нікому не секрет, що GC є дуже важливою річчю в JVM, і що вона займається звільненням памяті, що вже не використовуються. Також багатьом відомо, що є кілька різних політик виконання очистки пам'яті. Конфігурація не виглядає надто складною, є всього кілька можливих варіантів вибору політики GC:
- SerialGC - встановлена по дефолту, працює найкраще якщо на машині тільки один процесор, коли виконуєть збір сміття, то програма тормозить, адже в даний момент вона не відповідає.
- ParallelGC - використовується можливість виконувати мінорний (minor) збір сміття в паралельних потоках. Програма здатна відповідати на запити клієнта в момент збору сміття
- ParallelOldGC - виконує мажорний (major) збір сміття в паралельних потоках
- ConcMarkSweepGC - В даному випадку постійно відбувається збір сміття, програма не тормозить при зборах сміття, як це можна замітити в 3 попередніх випадках.
Таким чином, я вирішив переконфігурувати для прикладу IntellijIdea, що я використовую.
-Xms256m
-Xmx512m
-XX:MaxPermSize=120m
-XX:+UseConcMarkSweepGC
-ea
-Dawt.useSystemAAFontSettings=lcd
Для покращення швидкодії роботи, можна також установити значення ms = mx, так щоб
-Xms512m
-Xmx512m
-XX:MaxPermSize=120m
-XX:+UseConcMarkSweepGC
-ea
-Dawt.useSystemAAFontSettings=lcd
Ресурси
- Java SE 6 HotSpot[tm] Virtual Machine Garbage Collection Tuning - із серії must-read
- Java HotSpot VM Options - якось давно шукав подібну документацію, тепер повезло більше - знашов.
- Tuning Garbage Collection Outline - цікава підбірка фактів про GC
Subscribe to:
Posts (Atom)